Introduction
Most companies do not have a data problem in the simple sense. They have plenty of data. The real problem is that the data is scattered across billing tools, CRMs, product databases, support chats, spreadsheets, marketing platforms, and a few legacy systems nobody wants to touch on a Friday afternoon.
Contents:
And then somebody asks a basic question like, “Which users are likely to churn next month?” or “Why did revenue drop in this region?” Suddenly the team realizes that the answer is not in one clean place. It is hiding in six tools, three naming conventions, and a report that only one person knows how to update.
This is where data engineering services become useful.
Good data engineering turns messy, disconnected information into reliable pipelines, clean models, warehouses, dashboards, and data products that people can actually trust. It gives analytics teams better inputs, product teams clearer signals, and executives fewer “let me check that and get back to you” moments. You agree, that sounds good, doesn’t it?
Let’s uncover how data engineering solutions work and how you can leverage them in your processes.
Key Takeaways
What is Data Engineering
It includes the design, development, migration, integration, and maintenance of systems that collect, transform, store, monitor, and deliver data. IBM describes data engineering as building systems for aggregating, storing, and analyzing data at scale. That definition is a bit textbook-ish, but it gets the point across.
In plain English, data engineers build the roads your data travels on. They connect sources, clean up incoming records, shape data into useful models, set up storage, automate processing, and make sure the whole thing keeps working when traffic grows or source systems change.
A typical data engineering project may include:
- Auditing existing data sources and reporting flows
- Building batch or real-time data pipelines
- Creating ETL or ELT processes
- Setting up a data warehouse, lake, or lakehouse
- Integrating APIs, databases, files, and third-party platforms
- Cleaning, deduplicating, and standardizing records
- Building data models for analytics and visualization
- Adding monitoring, alerts, access control, and documentation
- Preparing datasets for AI, machine learning, or advanced analytics
Data engineering services are not just backend work, although there is plenty of backend thinking involved. It sits somewhere between software engineering, analytics, infrastructure, and product strategy. That mix can be awkward at first. But when it works, the business stops arguing about which spreadsheet is right and starts asking better questions.
Data Engineering vs. Data Analytics vs. Data Science
These three areas get mixed together all the time, and honestly, the confusion is understandable. They all deal with data. They often use some of the same tools. In a smaller company, one person may even do a bit of everything.
Still, the roles are different.
Data engineering is about building the foundation. Engineers create pipelines, storage layers, data models, quality checks, and infrastructure. Their job is to make data available, consistent, secure, and usable.
Data analytics is about interpreting that data. Analysts build reports, dashboards, forecasts, cohort views, revenue breakdowns, funnel analysis, and all the other materials teams use to understand what is happening.
Data science goes a step further into modeling, prediction, experimentation, and machine learning. A data scientist might build a fraud detection model, a recommendation engine, or a churn prediction system.
Here is the thing: analytics and data science are only as good as the underlying data. If the pipeline is unreliable, the model will not be magically smart. It will just be confidently wrong, which is worse.
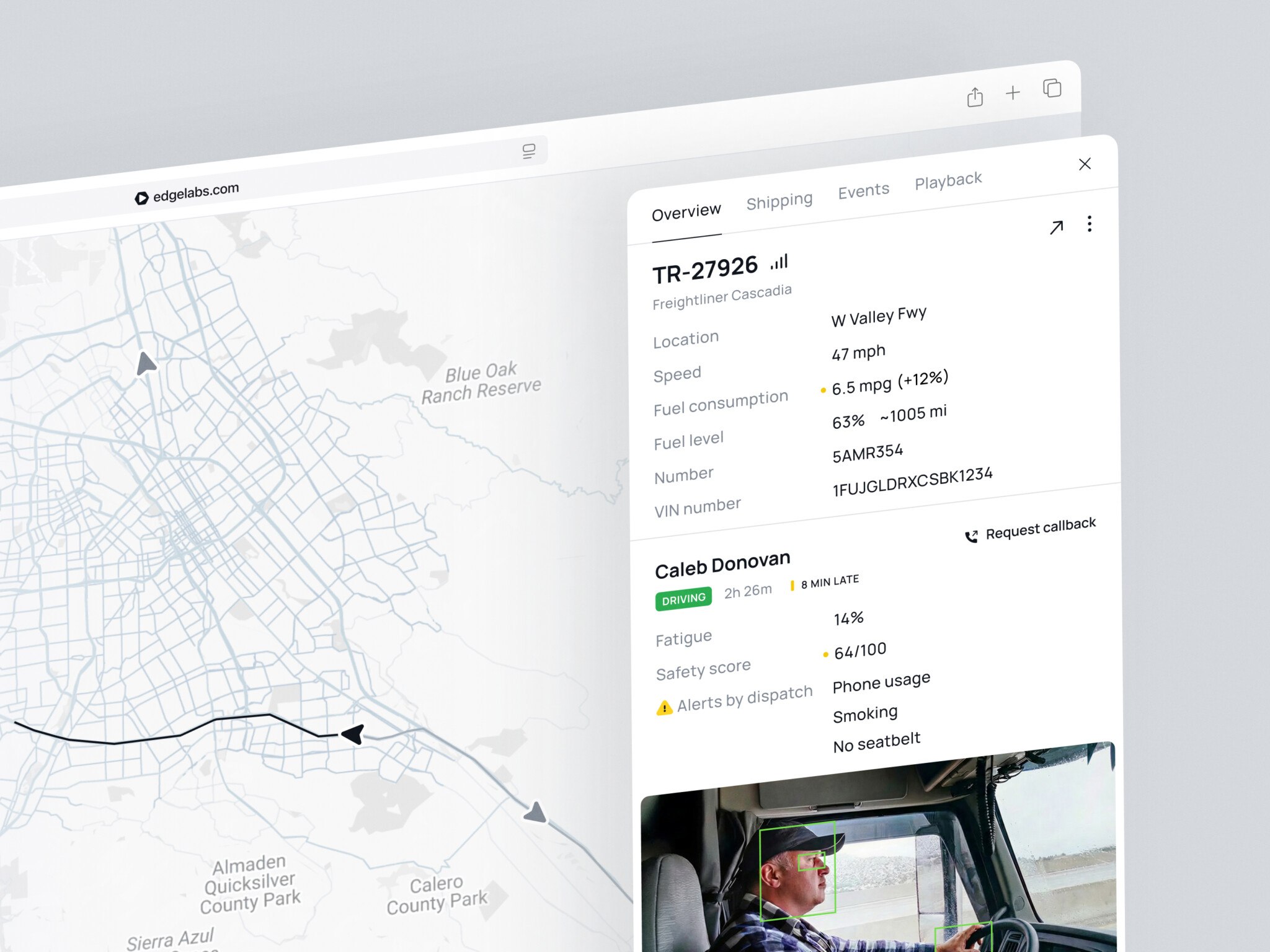
ERP dashboard by Shakuro
Why Data Engineering Matters for Modern Products
Modern products generate data constantly. Every signup, payment, click, search, refund, support message, feature flag, and API event tells a small part of the story. On its own, one event may not mean much. Together, the events can show where the product is working, where people get stuck, and where money is leaking out.
But only if the data is usable.
For a SaaS company, custom data engineering solutions can connect billing, product usage, support activity, and customer health into one view. This allows teams to spot churn risks before they lead to cancellations. In fintech, stable data pipelines can aid in risk monitoring, transaction analysis, reporting, and fraud detection. In healthcare, they can help standardize operational or patient-related data while still following privacy rules. In e-commerce, they can connect inventory, user behavior, promotions, and revenue so that teams are not guessing what happened after a campaign.
And one more point: data engineering is becoming more important because of AI. Everyone wants smarter automation, better personalization, and AI assistants inside their products. Fair enough. But AI systems need clean, well-structured, well-governed data. Otherwise, you get impressive demos and disappointing production results.
It is a little annoying, because data preparation is not the flashy part. But you get used to it over time. The foundation matters.
Core Services Companies Usually Need
The exact scope depends on the product, but most companies need some version of the same core work.
Data Strategy and Audit
Before building anything, someone needs to look at the current state of data. Which systems produce it? Which teams use it? Which reports are trusted, and which ones make people frown during meetings?
A data audit usually maps sources, owners, quality issues, access rules, duplication, reporting gaps, and business priorities. It is not glamorous. I keep saying that because it is true. But it saves a lot of pain later.
This is also where data engineering consulting can be helpful. A good outside team can ask naive but necessary questions. Why does “active user” mean one thing in product analytics and another thing in finance? Why are two dashboards showing different revenue? Why does the CRM have three versions of the same company? These details sound small until they start driving decisions. But we will dwell on outsourcing a bit later.
Pipeline Development
Pipelines move data from source systems to storage and analytics layers. Some run once a day. Some run every few minutes. Some process streams in near real time.
A pipeline may pull data from a database, API, event stream, CSV file, mobile app, or third-party SaaS tool. Then it validates, transforms, enriches, and loads the data into a target system.
AWS explains a data pipeline as a way to move and process data from one or more sources so it can be used by applications, analytics, and machine learning systems.
That sounds neat on paper. In real projects, the source API changes, fields arrive empty, time zones fight each other, and somebody sends a CSV with a renamed column. Good pipeline design expects this. It does not assume everything will behave.
ETL and ELT Implementation
ETL means extract, transform, load. Data is pulled from sources, cleaned or shaped, and then loaded into a central repository such as a data warehouse. AWS describes ETL as a process for combining data from multiple sources into a large central repository.
ELT means extract, load, transform. In this approach, raw or lightly prepared data is loaded first, and transformations happen inside the warehouse or cloud data platform.
Which one is better? Well, annoying answer: it depends.
ETL can be useful when data needs heavy cleaning before it reaches storage, especially in regulated or tightly controlled environments. ELT often fits modern cloud warehouses, where storage is cheap enough and teams want flexibility to rebuild models later. Many real systems use a mix of both. There is no medal for ideological purity here.
Data Warehouse, Lake, or Lakehouse Setup
A data warehouse organizes structured data for reporting and analysis. A data lake stores larger volumes of raw or semi-structured data. A lakehouse tries to combine the flexibility of a lake with the reliability and query performance of a warehouse.
The right option depends on data volume, team maturity, budget, compliance needs, and use cases. A young SaaS startup might be fine with PostgreSQL, dbt, and a managed warehouse. A financial platform with heavy event streams, historical analytics, and model training needs a more serious setup.
The worst choice is usually the one made because a tool is fashionable. Many teams buy far more platform than they needed, then spend months trying to justify it. Start with the business need. Then choose the stack.
Data Integration Services
Most products do not live alone. They exchange data with CRMs, billing platforms, ERP systems, payment providers, analytics tools, ad networks, support systems, identity providers, and internal databases.
Data integration services connect these systems and make the data usable across them. That may mean API integrations, database replication, event tracking, file imports, webhook processing, or custom connectors.
The tricky part is not always moving the data. It is making sure the meaning survives the trip. A “customer” in Stripe is not always the same as a “customer” in HubSpot or a “workspace” in a SaaS app. The mapping matters.
Data Quality, Governance, and Observability
Data quality sounds like one of those dry enterprise phrases. But it really means, can people trust this number?
Quality checks can catch missing fields, duplicate records, invalid values, broken joins, unusual volume changes, and late-arriving data. Governance defines ownership, access rules, privacy constraints, retention policies, and documentation. Observability adds monitoring and alerts so teams know when pipelines fail or outputs drift.
Without this layer, data platforms age badly. They still run, technically. But everyone stops believing them.
CRM dashboard design by Conceptzilla
Data Pipeline Architecture: How Reliable Data Flows Work
Reliable, custom data engineering solutions usually have a few familiar layers.
First, there are source systems: application databases, logs, APIs, event streams, files, third-party tools, and sometimes old internal systems with names nobody remembers choosing.
Then comes ingestion. This is where data enters the pipeline. Ingestion can happen through scheduled jobs, change data capture, message queues, API calls, file drops, or streaming tools.
After that, the data is stored somewhere. Depending on the architecture, this might be a raw storage layer, staging tables, a warehouse, a lakehouse, or a combination of these.
Transformation comes next. Data gets cleaned, joined, standardized, enriched, aggregated, and reshaped into models that match business concepts. For example, raw product events become sessions, sessions become engagement metrics, and engagement metrics become customer health scores.
Finally, the data is served to dashboards, analytics tools, APIs, machine learning models, internal apps, or customer-facing visualization platforms.
Around all of this, you need orchestration, testing, monitoring, access control, and documentation. Those supporting pieces are easy to underestimate. But they are what keep the system from becoming a collection of clever scripts that only one developer understands.
Batch vs. Real-Time Pipelines
Batch pipelines process data on a schedule. Hourly, daily, weekly, whatever the business needs. They work well for financial reporting, historical analysis, operational dashboards that do not require second-by-second updates, and many marketing or product metrics.
Real-time pipelines process data as it arrives. They are useful for fraud detection, live trading analytics, system monitoring, user personalization, logistics tracking, and time-sensitive alerts.
Real-time sounds exciting, and sometimes it is necessary. But it is also more complex. You have to think about ordering, retries, duplicates, late events, backpressure, and monitoring. If a daily batch job solves the business problem, use the daily batch job. No shame in that.
ETL vs. ELT in Practice
The ETL pipeline model is familiar because it has been around for a long time. Extract data, transform it into the right shape, load it into the warehouse. Clean, controlled, predictable.
ELT became more popular with cloud warehouses and scalable storage. You load first, then transform. This can make teams faster because they keep raw history and rebuild models when business logic changes.
For example, a SaaS company may load raw signup events, subscription changes, and product events into a warehouse. Later, analysts can create models for activation, retention, trial conversion, and expansion revenue. If the definition of activation changes, they do not need to re-ingest everything. They update the transformation logic.
That flexibility is great. But it needs discipline. Without naming conventions, ownership, tests, and documentation, ELT can turn into a very expensive attic.
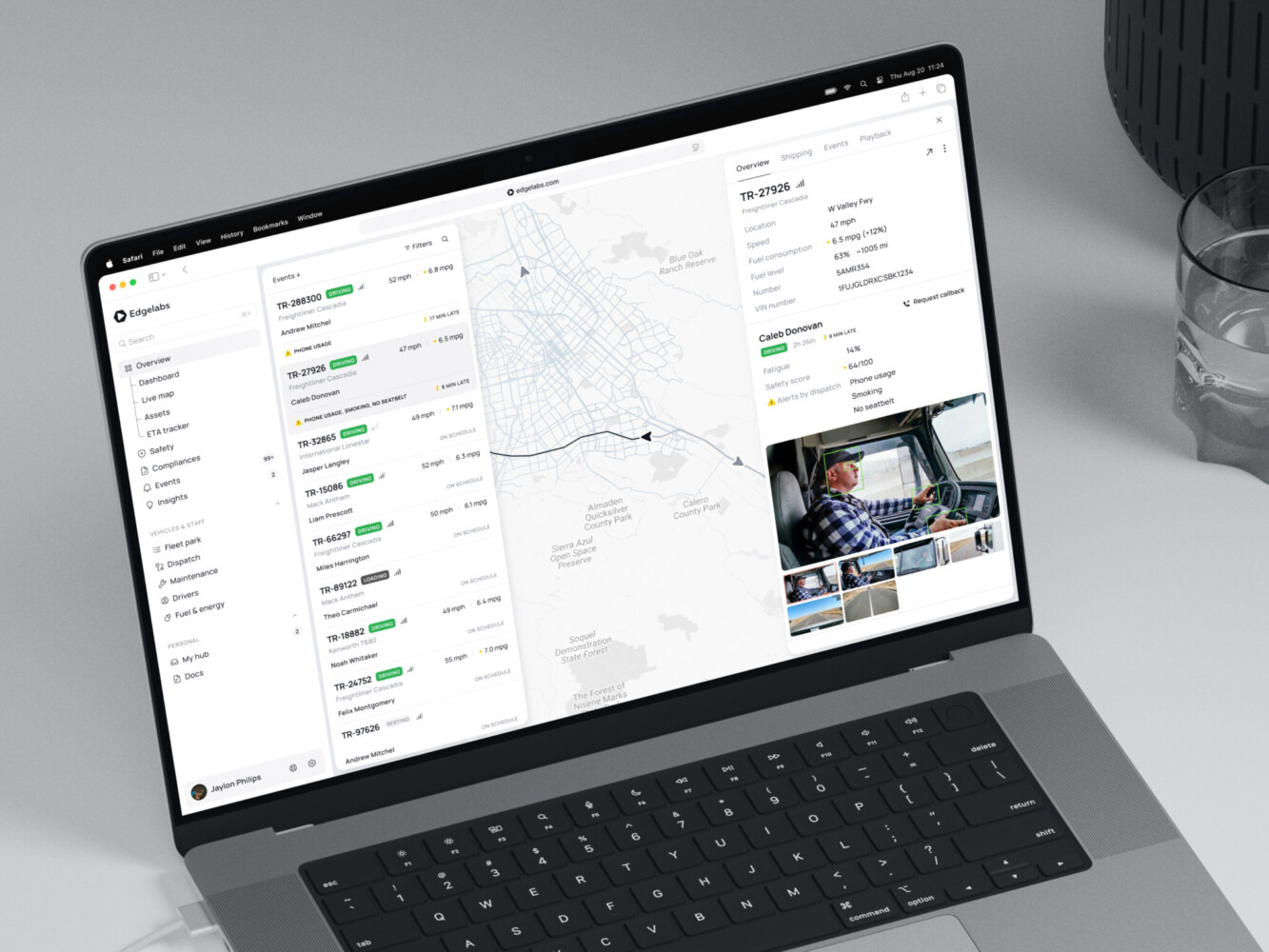
Telematics Dashboard by Shakuro
Data Engineering Tech Stack
There is no universal best stack for data engineering solutions. There are only stacks that fit a team, a product, a budget, and a set of constraints.
Still, some tools appear often:
- Python for pipeline logic, automation, integrations, and data processing
- SQL for transformations, modeling, and analysis
- Kafka or RabbitMQ for event-driven systems and streaming-style architecture
- Spark for large-scale distributed processing
- Airflow, Prefect, Dagster, or similar tools for orchestration
- dbt for analytics engineering and warehouse transformations
- PostgreSQL, MySQL, or MongoDB for application and operational data
- Snowflake, BigQuery, Redshift, or similar platforms for analytics storage
- AWS Glue, Google Dataflow, or managed cloud services for pipeline work
- Kubernetes and Terraform for deployment and infrastructure
- Prometheus, Grafana, Loki, or similar tools for monitoring and logging
For example, we use a broader range of engineering work that often touches similar ground: Python, FastAPI, React, Next.js, PostgreSQL, MySQL, MongoDB, Kubernetes, Terraform, Grafana, and other tools used in scalable web and analytics products. The important bit is not collecting logos for a tech stack slide. It is choosing tools your team can maintain six months later.
How to Build a Data Engineering Solution Step by Step
1. Discovery and Data Audit
Start with business goals. What decisions should the platform support? Which teams will use it? What reports, dashboards, models, or workflows are expected?
Then map the data. Sources, owners, refresh rates, formats, known issues, privacy constraints, and current manual work. This step often reveals funny little surprises. A metric that everyone quotes may come from a spreadsheet last updated by a person who left the company two years ago. It happens.
2. Architecture Planning
Plan how data will move through the system. Decide on batch or streaming, ETL or ELT, warehouse or lakehouse, cloud services, orchestration tools, security model, and monitoring approach.
This is also where tradeoffs should be made openly. A startup may care more about speed and low maintenance. An enterprise may care more about governance, lineage, and auditability. Both are valid. They are just different games.
3. Pipeline Design
Design ingestion, transformation, validation, and loading logic. Define retry behavior, error handling, schema rules, and data contracts.
Data contracts are especially useful when multiple teams work on the same product. They clarify what data producers promise to provide and what downstream systems can safely expect. Without that, one backend change can quietly break five reports.
4. Warehouse or Lakehouse Setup
Set up storage around real access patterns. Who queries the data? How often? How large are the datasets? What retention rules apply? Which datasets are sensitive?
A good model is easy to query, reasonably fast, and understandable. A perfect theoretical model that nobody can use is not a win.
5. Integrations
Build connectors for internal databases, third-party tools, APIs, event streams, and files. Handle authentication, rate limits, pagination, failures, and incremental updates.
This is one of those places where projects get slower than planned. Not because the team is weak, but because source systems are messy. APIs behave differently. Documentation is sometimes optimistic. You learn to add a buffer.
6. Data Quality and Security
Add tests for completeness, freshness, uniqueness, accepted values, and business rules. Set up access control, encryption where needed, privacy safeguards, and audit logs.
If the platform handles fintech, healthcare, or personal data, this is not optional. Even in a smaller SaaS product, you still need sane permissions. Not everyone should be able to see everything.
7. Dashboard and API Delivery
Once the data is clean and modeled, it can be delivered through dashboards, internal tools, customer-facing visualization platforms, or APIs.
This is where product design matters. A dashboard can have correct data and still be useless if it is hard to read. People need hierarchy, filters, sensible defaults, and labels written in business language. Nobody wants to decode a database schema during a Monday meeting.
8. Monitoring and Optimization
After launch, watch the system. Track pipeline failures, slow jobs, warehouse costs, missing data, source changes, and user behavior.
Data platforms are not “done” in the way a landing page might be done. They evolve with the product. New sources appear. Metrics change. Teams ask better questions. That is a good sign, actually. It means the platform is being used.
Marketing analytics dashboard by Shakuro
Common Data Engineering Challenges
The hardest part of data engineering for startups and growing companies is rarely one big dramatic issue. It is usually a pile of small ones.
Legacy data may be incomplete or inconsistent. Schema changes may break transformations. Different teams may define the same metric in different ways. Real-time systems may produce duplicate events. Cloud costs may creep up quietly. Access control may be too loose at first, then too strict later. Integrations may fail because a third-party API changed something without much warning.
Then there is ownership. Who fixes a broken metric? The backend team? The data team? The product manager? The analyst who noticed it? If nobody knows, the issue sits there.
Some practical ways to reduce the mess:
- Define business metrics clearly before building dashboards
- Use data contracts for important source systems
- Add automated tests for freshness, uniqueness, and accepted values
- Monitor pipeline runs and unusual volume changes
- Keep raw data where possible so transformations can be rebuilt
- Document models in language non-engineers can understand
- Control access by role, especially for sensitive datasets
- Review cloud costs regularly instead of after the bill hurts
None of this makes the work effortless. But it makes failure less surprising, which is already a big improvement.
How Much Do Data Engineering Services Cost?
The cost of data engineering services depends on scope, data complexity, integrations, compliance needs, and the level of automation required. Still, rough ranges help.
A small audit or MVP pipeline may cost around $15,000 to $40,000. This might include a few sources, one warehouse or database, basic transformations, and a simple dashboard or reporting layer.
A mid-size setup with a proper warehouse, several integrations, data models, quality checks, and analytics dashboards may land around $40,000 to $120,000.
An enterprise-grade platform with streaming, governance, complex security, many sources, observability, and advanced analytics can reach $120,000 to $300,000 or more.
The biggest cost drivers are usually the following:
- Number and complexity of data sources
- Data volume and refresh frequency
- Batch vs. real-time requirements
- Compliance and security rules
- Cloud infrastructure choices
- Quality and observability needs
- Dashboard, API, or visualization complexity
- Ongoing support and maintenance
One quiet cost driver is unclear requirements. If the team does not agree on what a metric means, engineers will rebuild the same model several times. It is painful, and it is avoidable.
SaaS marketing dashboard by Conceptzilla
Shakuro’s Experience With Data-Heavy Products
We have worked on products where data is not just a background detail. It is part of the product’s value.
One relevant example is Symbolik Social, a social platform for financial analysts connected to the Symbolik ecosystem. The platform had to support financial professionals, watchlists, discussions, real-time interactions, and a complex information architecture.
The product needed reliable data flows, responsive interfaces, real-time updates, and careful handling of financial-context features. To provide that, our team used Next.js, React, TypeScript, C#, ASP.NET Core, MySQL, WebSockets, RabbitMQ, Auth0, Serilog, Grafana Loki, Hangfire, and AWS S3.
Dashboards and AI tools depend on the quality of the data layer underneath them. In other words, a beautiful analytics interface is only half the story. The other half is what happens before the chart appears. That’s why, when developing Symbolik, our backend and frontend developers closely collaborated to deliver a robust, easy-to-scale base.
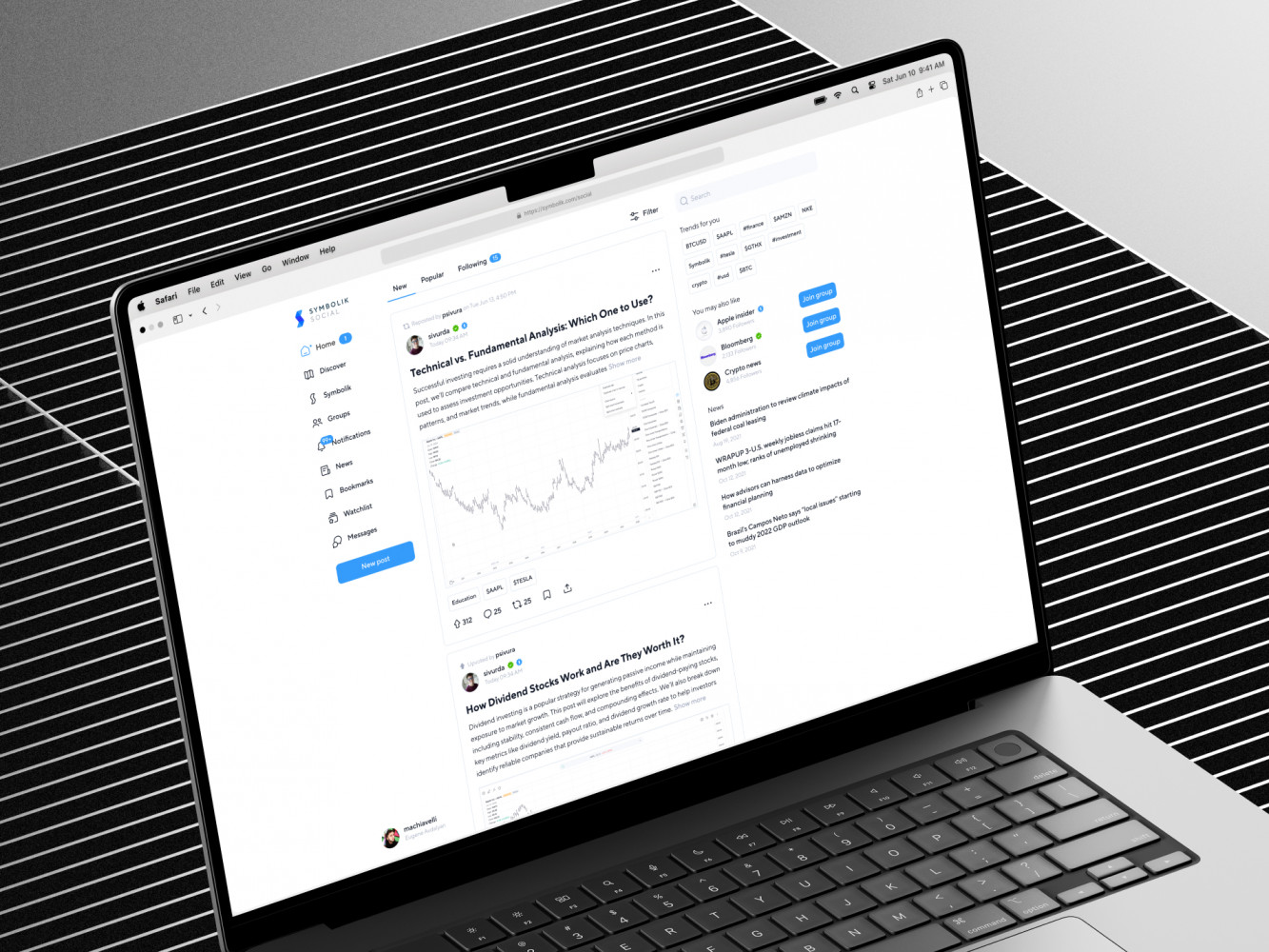
Symbolik case by Shakuro
Why Bring In a Data Engineering Services Company
You can build a data platform in-house. Many companies do. If you already have strong backend, data, DevOps, and analytics people, that may be the best option.
But a data engineering services company can help when the team is moving fast, the architecture is unclear, or the product has grown beyond its original data setup. External engineers bring a fresh view. They can design the architecture, build pipelines, connect systems, set up dashboards, clean up legacy flows, and leave behind a structure your team can keep using.
This is especially useful when the product crosses several disciplines: backend development, cloud infrastructure, UI/UX, analytics, AI, security, and long-term support. Data platforms touch all of them.
A good partner should not just ask, “Which tool do you want?” They should ask:
- What decision will this data support?
- Who needs the result?
- How fresh does it need to be?
- What happens if the pipeline fails?
- Which data is sensitive?
- Who owns each metric?
- What will change when the product scales?
Those questions are not flashy, but they are the difference between a platform that works and a platform that becomes another internal headache.
Final Thoughts
Data engineering for startups is not just plumbing. It is the foundation for analytics, automation, AI, reporting, and better product decisions. Without it, teams spend too much time reconciling numbers and not enough time acting on them.
The good news is that you do not need to build a massive enterprise platform on day one. Start with the business questions that matter. Map the data sources. Build the first reliable pipelines. Add quality checks. Create models people understand. Then grow from there.
Need a reliable data foundation for your product? Shakuro can help design and build scalable pipelines, dashboards, and data platforms for SaaS, fintech, healthcare, e-commerce, and other data-heavy products.
Sales Analytics Dashboard by Shakuro
FAQ
What does this work include?
Typically these include data audits, building of pipelines, ETL or ELT, setting up of data warehouses or lakehouses, integrations with APIs and databases, data quality checks, governance, monitoring, preparation of dashboards, and ongoing support.
How long does a data engineering project take?
A small audit or MVP pipeline may take a few weeks. A mid-size analytics platform can take two to four months. Larger systems with streaming, governance, many integrations, or strict compliance requirements may take six months or more. It depends on the messiness of the source data, honestly.
What is the difference between ETL and ELT?
ETL extracts data, transforms it, and then loads it into the target system. ELT extracts data, loads it first, and transforms it later inside the warehouse or cloud data platform. ETL gives more control before storage. ELT often gives more flexibility for modern analytics teams.
Do startups need data engineering?
Not always at the very beginning. A simple database and a few reports may be enough. But once the startup has multiple data sources, growing customer activity, investor reporting, product analytics, or AI plans, data engineering becomes much more important. Waiting too long can make cleanup harder.
How do you make data pipelines secure?
Use role-based access, encryption where needed, secure credential storage, audit logs, network controls, privacy rules, and data masking for sensitive fields. Also, limit who can access raw data. That one sounds basic, but it really helps.
What tools are used in data engineering?
Common tools include Python, SQL, Airflow, dbt, Kafka, Spark, PostgreSQL, MySQL, MongoDB, Snowflake, BigQuery, Redshift, AWS Glue, Google Dataflow, Terraform, Kubernetes, Prometheus, and Grafana. The best option depends on the project, not on which tool is trending this month.