
Are you tired of dealing with the headaches that come with maintaining and scaling your applications? Do you find yourself drowning in a sea of spaghetti code and tangled dependencies? It’s time to take control of your app structure and create a solid foundation that will not only improve the performance of your project but also make your life as a developer much easier.
Contents:
In this article, we will share the principles of the app architecture we adopted in recent years that proved to be reliable and flexible enough for sustained backend and web development, including further maintenance of our products. When the software has a clear structure based on rules and guidelines, everyone knows where to look for things and where to put new pieces they introduce.
We will talk about the API-only backends here, so you will not find where to put your HTML templates. After getting a feel of how things tick, you should get a feel for the right place for this code.
The architecture of the application is largely based on the ideas of “Hexagonal architecture” and works well for projects of various shapes and sizes. Since it involves a specific structure and certain discipline, sometimes it might be an overkill to implement it to the letter. Also, the principles mentioned here aren’t new and by no means specific to Python, although they help the implementation.
App architecture principles
Ports and Adapters
Hexagonal Architecture or Ports and Adapters architecture was invented more than 20 years ago by Alistair Cockburn. Since then it has gone through several rounds of criticism and evolutionary transformations. Its latest “incarnation” is in the “Clean Architecture” coined by Robert C. Martin in 2012 where he combined principles of Hexagonal, Onion, and several other architectures and principles.
The essence is in breaking the whole application into components and connecting them loosely through ports and adapters so that there’s no direct coupling between them. To put it simply, you define what APIs are necessary and how to communicate with them, and later, you provide the concrete implementations.
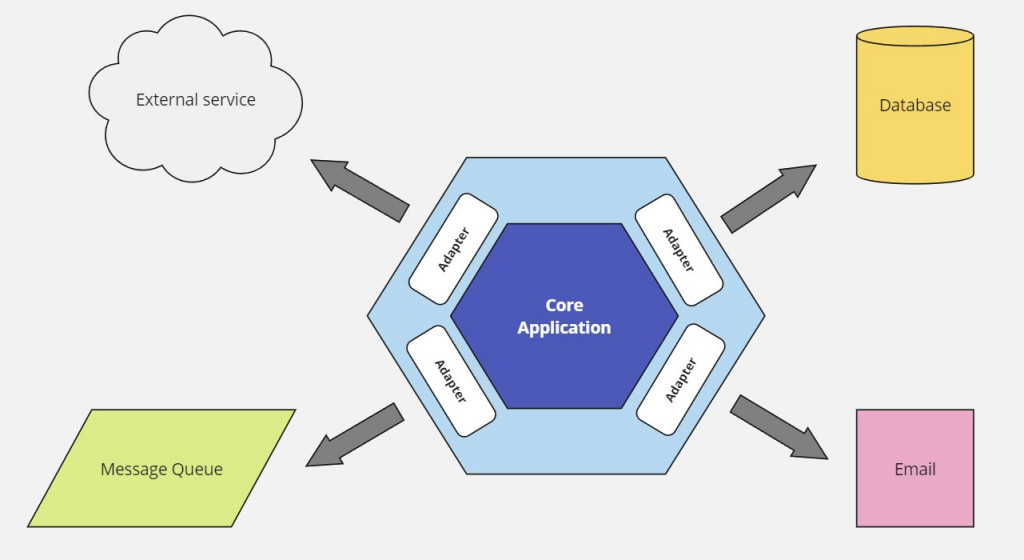
Imagine that your application needs to send notifications and save data to some storage. We would define APIs for these two components and then implement them by talking to an email gateway and a relational database respectively.
Dependency injection
Components need other components to do their work. We implemented our component working with a relational database to store and retrieve data. Now we need to pass it on to the business logic function.
Each language has its means of doing that. It can be as simple as passing them to constructors in object-oriented languages, passing them as arguments in functional languages, or using special libraries. For Python programming language, there are several options. We chose it because it is both easy to grasp and full of nice features, like a Dependency Injector.
In the world of DI, it’s common to think of dependencies organized into Containers. They hold resolution rules and provide initialized instances on demand. It becomes extra convenient when you get to test your code. By overriding resolution rules in your containers, you have precise control over what your dependents receive.
Here’s a tiny example of what such a container definition could look like. Here we define a sample container, pieces of which we’ll examine one by one in the following sections.
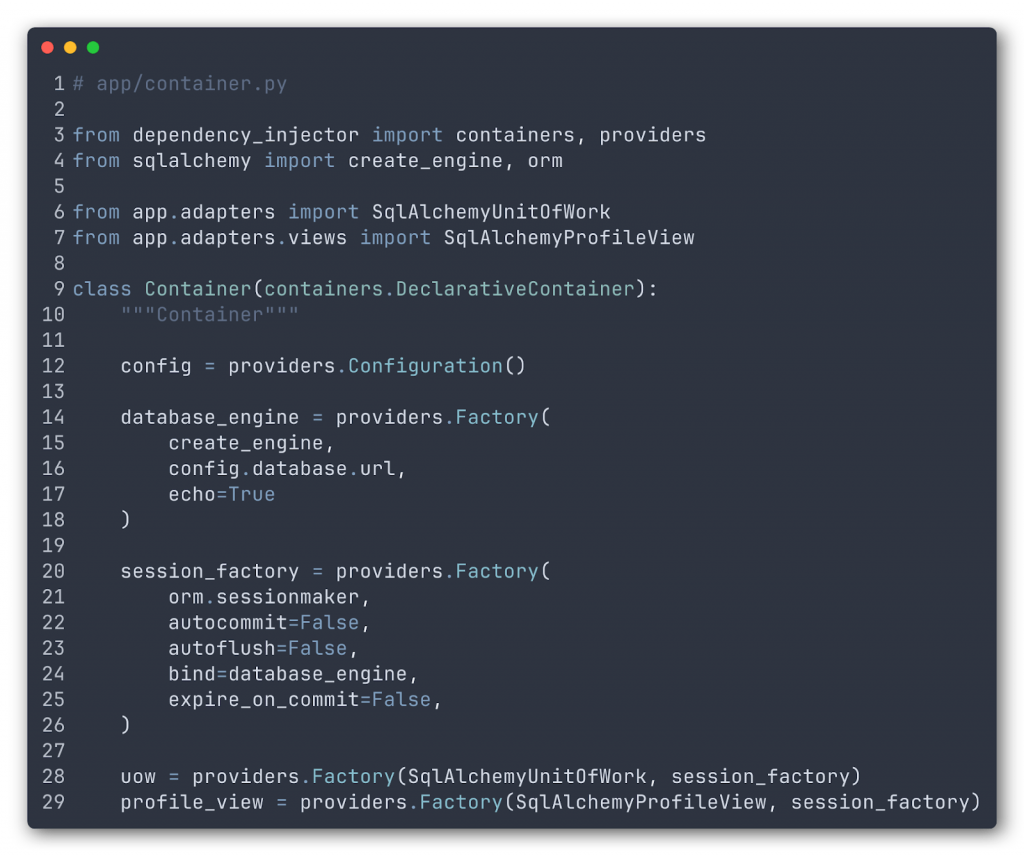
After the container is defined we just decorate our code so that it receives whatever it needs at run time. (The details of the implementation correspond to the Dependency Injector library.)
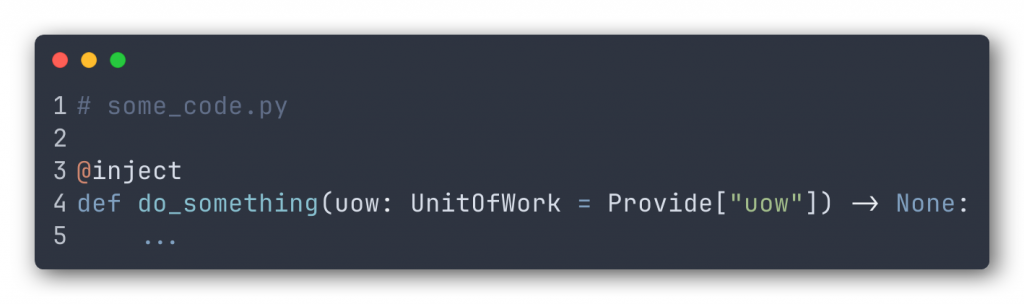
At this point, you might have these questions:
- What dependency types can be there (lambdas, objects of a certain type, configuration)?
- What should go as a dependency?
- Should I keep making instances of classes myself, or just define them in containers and let factories produce them?
Take it slowly. There are certain things that you should extract into injectable dependencies (and we’ll talk about them next). There are things that you may or may not extract. The primary suspects are expensive external dependencies – databases, file storages, email / SMS gateways, and other remote services. We will talk about how we work with local data next, and here’s something you may find entertaining to think about in the meantime.
(side note) Assume that you have some business logic that uses current time (scheduling future reminders, recording time of order fulfilments — there are plenty of such things). How do you test these? Freezing time, or not testing at all? What if you had an injectable “source of time”? In production, it comes from stdlib and provides the real moment in time, and in your tests, it could be set to any fixed moment. Would it make your time-based logic easier?
Working with data in Python app development
How do you work with data storage? Where does your data access code live? How do you test your business logic that relies on data? These are all related questions that we want to answer here.
Chances are that in your app you are persisting data and that you are using a relational database for that. If so, there are other methods for working with data in app architecture. For example:
Transaction Script. In simple terms, here we take a connection to a database and execute commands on it (for example, raw SQL). We can fetch or store data this way, but it clearly fits only the simplest scenarios. This programming pattern is great for scripts, however, it quickly becomes tedious to support the growth.
Active Record. Here we have objects (clearly for object-oriented languages) that are not just a bag of fields but also sprinkled with methods like find and save to provide data access. This one is generally good for small to middle-sized apps or when there’s not much going on except the standard CRUD operations. In this case, we generally don’t mind mixing our domain functions with persistence operations.
Data Mapper. Here we have objects (or structures) that know nothing about concepts outside their domain. They don’t provide any persistence operations. They are purely domain objects with domain-specific methods. It’s the flip side of the coin and you need to consider which way is better for you. Your persistence code is supposed to be fully external. It’s in the term. You provide the mapping of your model data to a database.
When you decide on the approach, you have several aspects to consider. As mentioned, if all your logic does is saving and loading data, then Active Record may be a great choice because of its simplicity. When you have complex logic in your domain, then you may want to lean towards Data Mapping. Data Mappers are generally a great thing; they are just a little bit involved in the process.
Repository Pattern
Data Access Objects (or DAO) are having a comeback in web and backend development. The beauty of the Data Mapping approach is that you separate concerns. Domain model and your classes are one thing, storing them is another. You may want to change your storage preferences along the way and it won’t affect your business code a tiny bit. Moreover, you may want to test your business logic extensively and there won’t be a need to store complex data structures in the database beforehand, so you have all set up for that one test case.
If you built web based application architecture on Python, no doubt you heard of SqlAlchemy. It’s the data mapper. Either declaratively or imperatively, you define how you want your models to be stored and let the library do its magic. Using imperative definitions means you’re halfway to the clean repository implementation. If you don’t, you should consider using them. Declarative ways may look nicer, but at the same time, you pollute your models with storage concerns. Easier, but it’s not as pure as an imperative way.
The Repository Pattern is based on the idea that you have your data access methods (like listing objects, getting a certain object, and saving and deleting objects) focused in one place. You define an interface / abstract class, then implement it and give it to any business code that needs these functions. This way, the code depends on the Repository interface you defined, not knowing the concrete realization.
In the Python design pattern, you may choose to implement an adapter for an SQL database, the file system, in-memory, or completely blank versions depending on what you need. It abstracts away all the nitty gritty details that are not important to the users of the interface.
Let’s define a simple repository for user profiles and implement it with the memory hash for our tests. First, let’s define the model we are going to use.
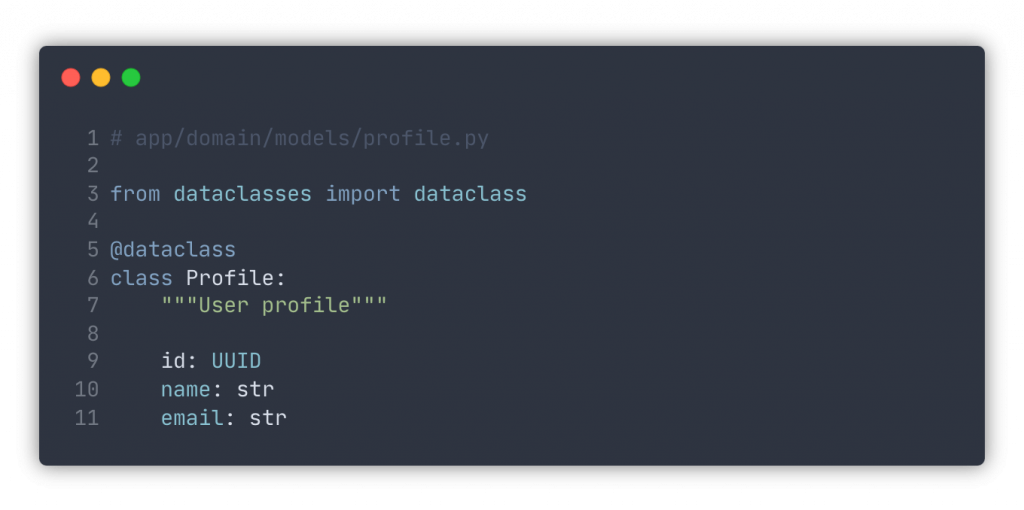
Now we define an interface of the abstract profile repository. Here we use abstract classes and methods. Python has another great feature – protocols — that may be a great fit too, depending on what you need. Note that we provide only signatures, but not the implementation of the repository methods.
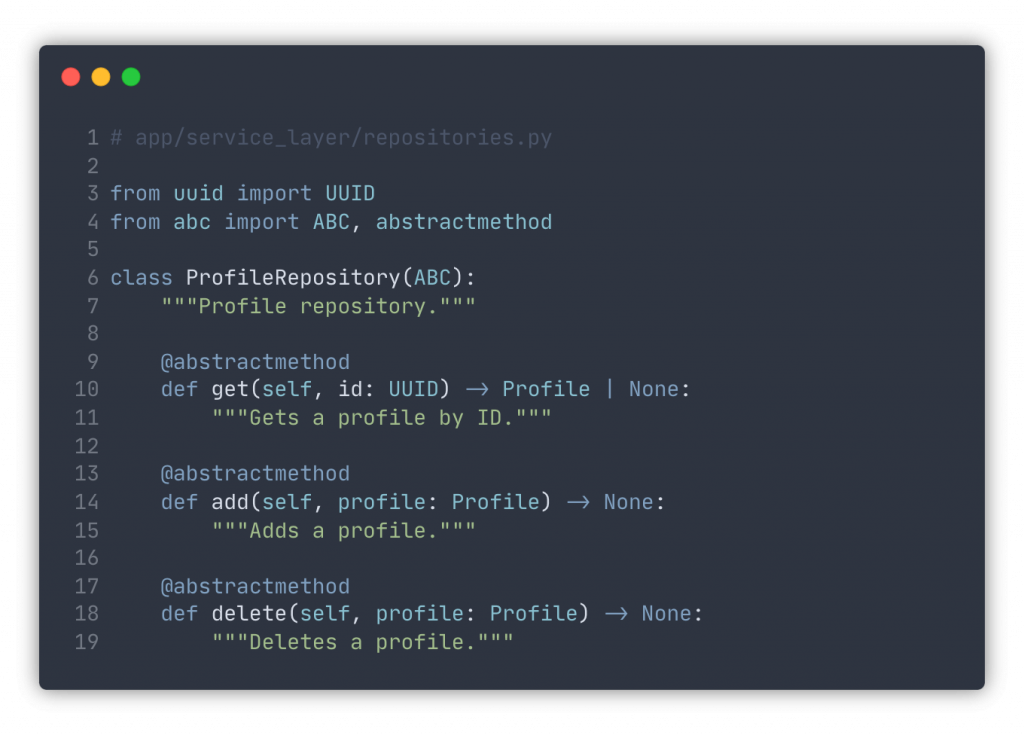
We are ready for our first implementation. Here’s an example of the in-memory version.
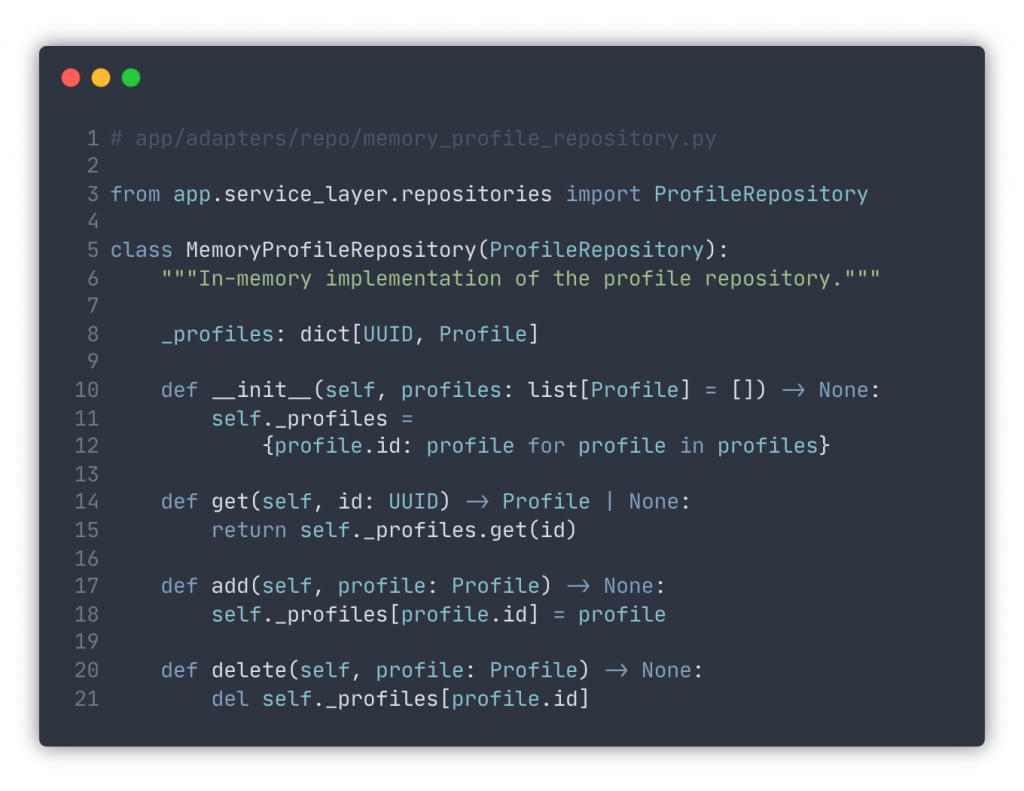
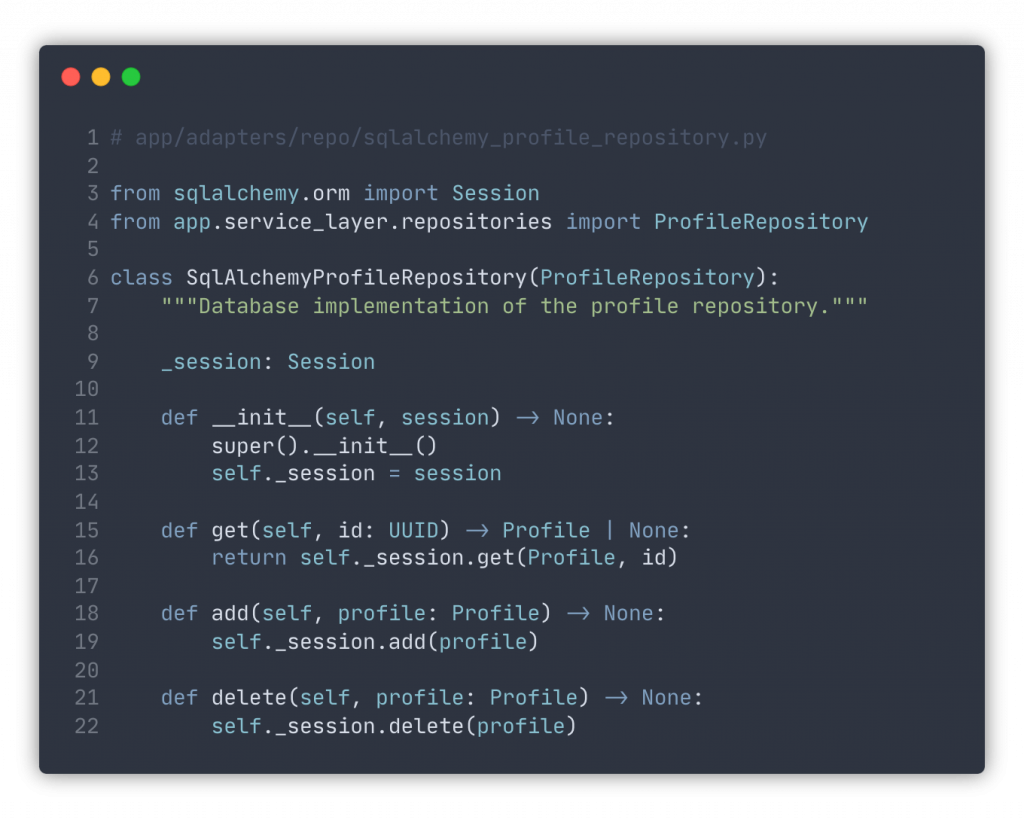
We can now use this in-memory implementation in our tests and forget about lengthy database populations and cleanup. For the production code, we can implement a similar one using a database session, like this:
Unit of work
Depending on the case, you may need to perform several business operations atomically. Imagine that you create a new user in your application. The user will need an account record, the profile record, and some other state you want to initialize in the database. You want either all of these if all is good, or none, if something goes wrong in the event. When your application uses a relational database (like PostgreSQL, for example), you would immediately think of transactions. These operations are seen as one unit of work.
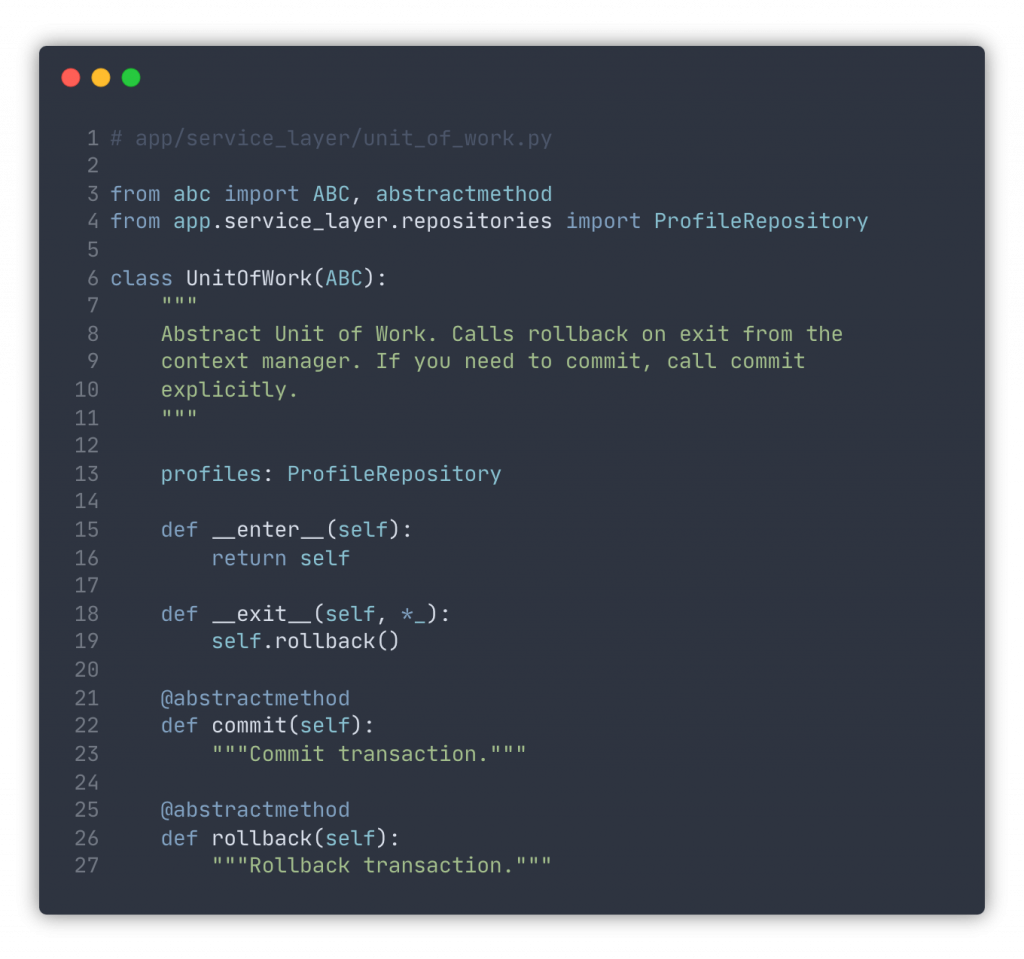
In Python app development, we design it such that our UoW implementation provides repositories. These repositories can be used to make changes and then these changes are either committed via UoW or rolled back. UoW handles the transactional wrapping for us.
Here’s the abstract interface of an example UoW with one repository, however, nothing stops you from having multiple of them under the same umbrella:
Here’s how one would use it in the function of creating a profile:
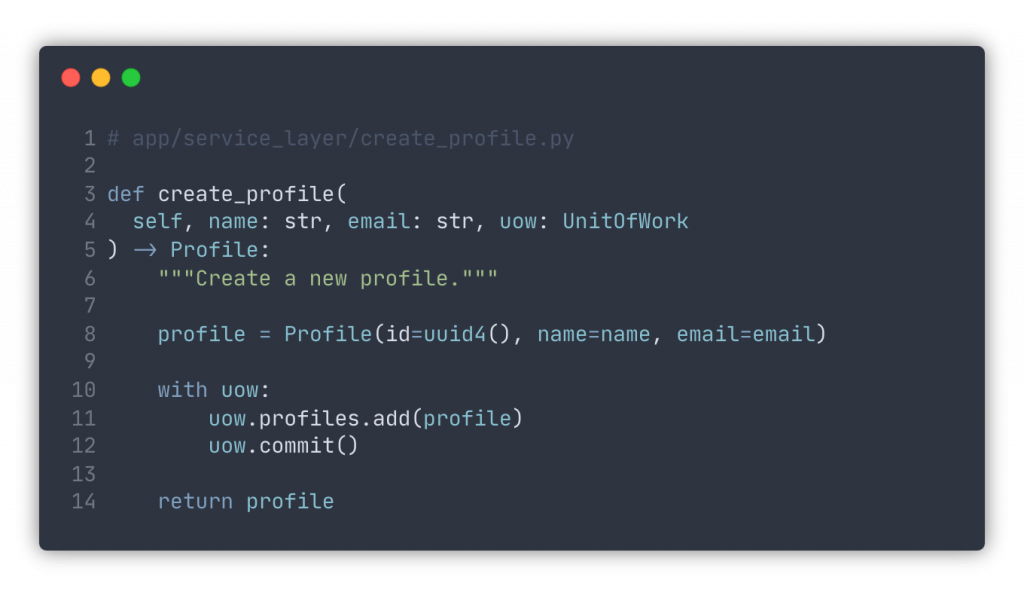
If we had more code between lines 8 and 9 and it failed, the commit wouldn’t happen and the unit of work wouldn’t be finalized. We aren’t speaking in terms of relational databases here. We just create a profile, add it to the repository, and commit the changes. How it’s implemented is not our concern.
Out of curiosity, here’s how we’d define our database implementation of the unit of work.

All nice and clean. We are implementing the desired Unit of Work interface in a database-specific way. We receive a SqlAlchemy session factory that is ready to provide us with the session when required. When we enter the context manager block, a new session is created, then a profile repository is created and initialized. Later, when we exit the block, we rollback (see the inherited behavior) and close the session.
(side note) Why do we always rollback on exit? That is a safeguard against accidental changes. It’s a great pattern that if you want to commit anything, you do that explicitly by calling commit. After changes are committed, rollback is a no-op, and nothing changes.
Views
When you need to query data from your database, consider using a programming pattern similar to Repository, except it usually has just one method that accepts filtering / pagination / sorting parameters, and any identifiers, and returns results. Just as with the repositories, we define our interface without referring to any concrete storage types, and then implement it for whichever we need.
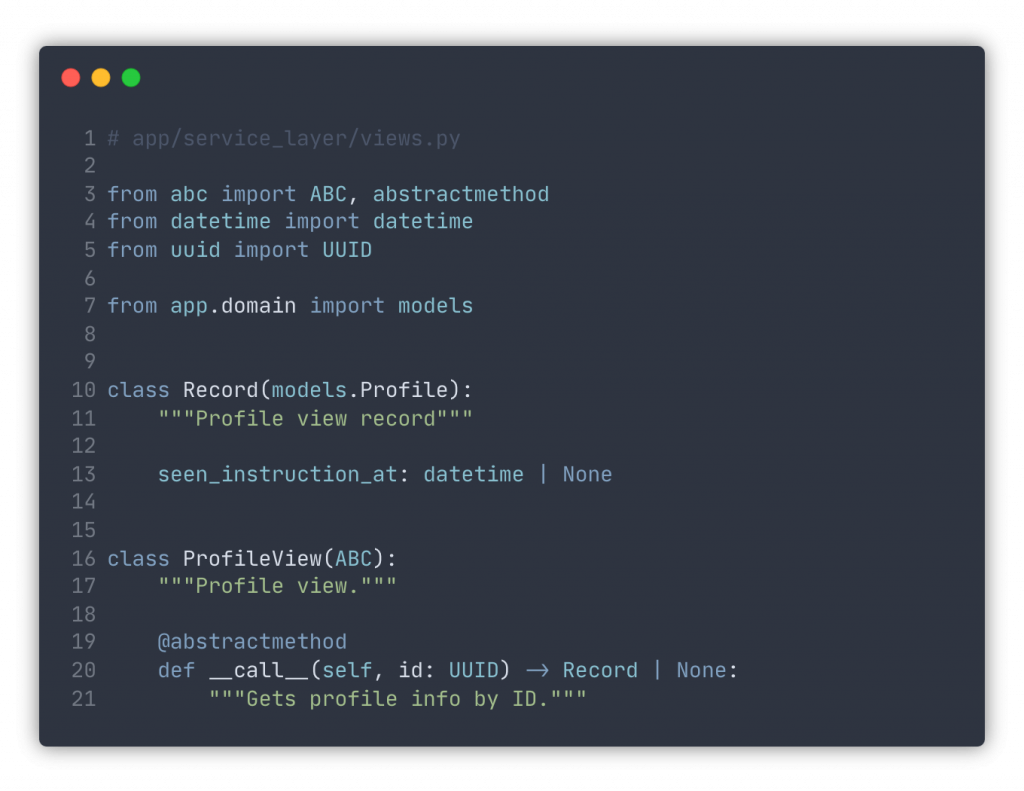
We define a Record that is mostly a Profile but with an additional field. This distinction is important.
Why not use repositories? Of course, if a single object is all that you need, you can use a repository to get it. Although we don’t recommend it as repositories are available through UoW with all that transaction / commit / rollback dance. Views are just an easier (and more focused) way to return data in the shape that you need.
Assume that you want to query a data set that joins several tables (in case you use a relational database as your storage) and you have models for each of them. How would you solve that with repositories? With a tailored view, you can define a record class to hold that specific data and then implement concrete view classes that return it (or the list of them).
What if there are many views in the app architecture? Don’t worry. It’s still better than many query statements scattered all over the code base. Each view implementation can be tested separately. Then in other places where a view is required, you can easily inject a fake view that provides necessary data for faster and straightforward testing.
Takeaways
- Group all your data access code into repositories and views.
- Use repositories to define interfaces for loading / persisting / deleting domain model objects. Create storage-specific implementations for production and tests.
- Introduce the Unit of Work concept that provides repository instances where you need them and use it to commit changes (or rollback if there was no explicit commit).
- Use views to define query interfaces. Implement concrete views for production and tests.
Business operations
We have domain objects representing our domain model. We know how to persist and load them back. Now we need to perform business operations that involve both. You’ve already seen one of them above named create_profile.
Often these business operations are called “use cases” and occasionally we’ve come across projects that had a package named like that with all possible cases implemented in separate classes. You may have as well. This is a great approach to separate operations / cases like that and organize them by context. Account-related operations may go to one folder, profile-related to another, and so on.
In the architecture of applications, we make each such operation class follow a similar pattern. Each receives dependencies either via the constructor (if the use-case is initialized as a class, just like “views”) and has a call method that makes it callable. It may receive arguments to customize the action further.
Another approach is to pass the dependencies into the module function with the rest of the arguments. This is what we did in that profile creation function above.
The beauty of this approach is that you have your operations nicely separated, easily tested, documented, and generally fun to work with. Your code has everything it needs to perform the task.
Takeaways
- Business operations (use cases) are a glue between your domain model and the external world.
- Each operation is either a class or a function that performs a certain operation on data while giving all dependencies and arguments.
- It is convenient to place use cases in a folder (we use app/service_layer for that). Start flat and organize them later into a deeper directory structure when you see clear groups emerge.
Communicating with the world
In backend or web development, you often need interfaces to access data from the outside. It can be an HTTP web server, CLI, message bus, or anything else. No matter what it is, the approach is the same. You have some function that either queries for data or performs changes. Queries, as we now know, are handled by views. Views are injected like anything else, and data is received and serialized to be returned.
Operations are usually not implemented right there in the web server handlers, CLI classes, etc., but rather placed in business operation classes (use cases). Then, they are called from the API endpoints as injected dependencies.
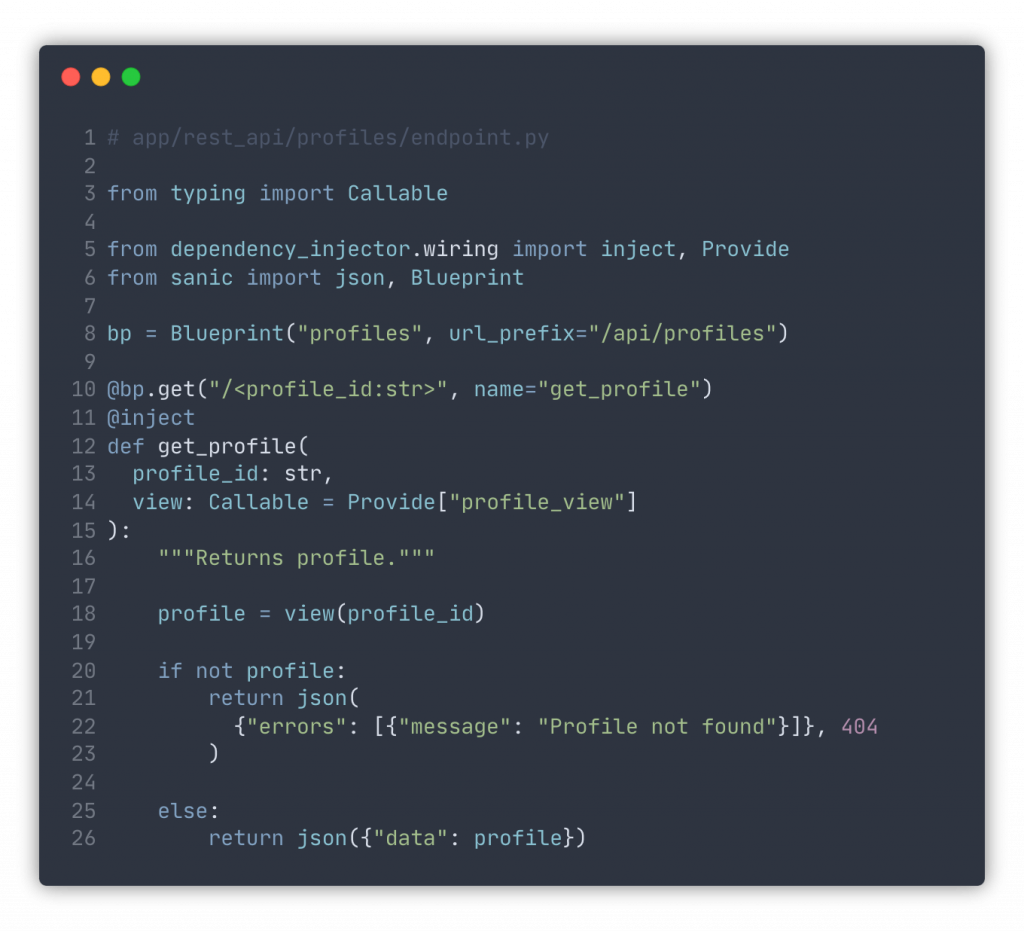
Takeaways
- Don’t perform any business logic in your endpoints. Leave it to use-case code nicely tucked in the service layer.
- Keep endpoints focused on what they are for – authenticating requests, receiving data, and serializing responses.
References
The ideas in this article are not invented by us. We put it to good practice before recommending it. If you want to go deeper and improve the design of your applications, we can’t recommend the following book enough:
- “Architecture Patterns with Python: Enabling Test-Driven Development, Domain-Driven Design, and Event-Driven Microservices” by Harry Percival, Bob Gregory, O’Reilly 2020
Conclusion
In conclusion, implementing a robust app architecture in Python is crucial for creating scalable, maintainable, and efficient applications. It will pay off in the long run, leading to better performance, improved code quality, and a more seamless development process. Additionally, incorporating unit testing, continuous integration, and code reviews into the development process can help identify and address any potential issues early on.
We hope this article helps you to build a better app structure. An app with a clear purpose and structure. Something easy to test and maintain.
Do you want to build an application with a solid structure? Contact us and let’s work together on your next project.
Written by Mary Moore and Aleksey Gureiev