
As a beginner or seasoned programmer, the struggle to stay updated on the latest trends and popular languages can be overwhelming. Fear not, as we have done the research for you and compiled a comprehensive guide to the most popular programming languages in the U.S.
In fact, the U.S. dominates a large share of the development market. It brought over 31.83% of the revenue share. The average salary in this sphere is around $100,076, according to Zippia. So, working with American customers is worth considering if you are a business owner or a developer.
Whether you are looking to expand your skill set or dive headfirst into the world of coding, this article will help you navigate the ever-evolving world of programming with ease. You will discover the languages that are in high demand for web and app development in the American market.

Top Web Programming Languages
In the USA, the trending programming languages can vary depending on factors such as the web industry landscape, the size of the community, and the types of projects being developed. Some of the top languages in the USA include JavaScript, Python, Java, and PHP:
- JavaScript: it’s widely used for front-end development. It is supported by all major browsers and can be used to create interactive and dynamic web pages.
- Python: this is a versatile language popular due to its simplicity, readability, and wide range of libraries and frameworks. It is used for back-end development, data analysis, machine learning, and more.
- PHP: PHP is a server-side language. It is known for its ease of use, scalability, and compatibility with various databases.
- Java: Java is used particularly for building enterprise-level applications. It is known for its robustness, security, and platform independence.
- Ruby: it is still popular in web development, especially when paired with the Ruby on Rails framework.
The Backbone of Software: Most Demanding Computer Language
The GitHub statistics below are based on the PYPL index, which analyzes how often people search for information and tutorials about certain languages on Google.
Ranking of Programming Language Popularity in the US (Jan 2025)
| Rank | Change | Language | Share | 1-year trend |
|---|---|---|---|---|
| 1 | Python | 34.24 % | +3.5 % | |
| 2 | Java | 14.23 % | +0.9 % | |
| 3 | ⬆⬆ | C/C++ | 8.18 % | +0.8 % |
| 4 | ⬇ | R | 8.15 % | +0.8 % |
| 5 | ⬇ | JavaScript | 6.78 % | -0.6 % |
| 6 | ⬆ | C# | 5.48 % | +0.0 % |
| 7 | ⬇ | Swift | 4.63 % | -0.9 % |
| 8 | ⬆ | Rust | 4.33 % | +0.9 % |
| 9 | ⬇ | Objective-C | 3.82 % | +0.1 % |
| 10 | ⬆ | TypeScript | 2.95 % | +0.8 % |
| 11 | ⬇ | Go | 2.36 % | -0.1 % |
| 12 | ⬆ | Matlab | 1.14 % | -0.7 % |
| 13 | ⬇ | PHP | 0.77 % | -1.1 % |
| 14 | ⬆ | Ruby | 0.62 % | -0.3 % |
| 15 | ⬇ | Powershell | 0.52 % | -0.6 % |
| 16 | ⬆⬆⬆⬆⬆⬆⬆ | VBA | 0.4 % | -0.0 % |
| 17 | ⬇ | Kotlin | 0.34 % | -0.6 % |
| 18 | Lua | 0.28 % | -0.2 % | |
| 19 | ⬆⬆ | Julia | 0.16 % | -0.3 % |
| 20 | ⬇ | Visual Basic | 0.13 % | -0.4 % |
- With a huge 34.24% share and consistent increase of +3.5% over the previous year, Python keeps ruling the programming scene. Its adaptability and broad application in disciplines such artificial intelligence, data science, and web development maintains it in ahead of others.
- With 14.23%, Java stays a strong second, just marginally changing by +0.9%. Still a go-to for business applications and Android development, it shows its endurance.
- Third at 8.18% is C/C++, with a little +0.8% gain. Its performance efficiency keeps it current in game creation and system-level programming.
- R is hot on its heels at 8.15%, also rising by +0.8%. Its increasing popularity in statistical computing and data analysis keeps going.
- Considered the pillar of web development, JavaScript sits at 6.78% but has slightly dropped -0.6%. Still, front-end and full-stack developers find it absolutely vital.
- At 5.48%, C# is constant and shows no notable variation. Thanks to Unity, it’s a major actor in both business apps and game creation.
- Especially noteworthy are Swift and Rust. Swift, at 4.63%, has dropped somewhat by -0.9%, maybe in response to mobile development rivalry. Rust‘s emphasis on performance and safety is helping it to acquire momentum at 4.33%, rising by +0.9%.
- Rising at 2.95%, TypeScript is up by +0.8%. Its expansion is being facilitated by its acceptance in major JavaScript initiatives.
- PHP and Ruby keep falling; PHP at 0.77% (-1.1%) and Ruby at 0.62% (-0.3%). Modern substitutes are taking front stage over some of the more ancient web building languages.
- Reflecting the competitive nature of the programming world, other languages such Go, Kotlin, and Dart are holding steady or showing slight dips.
- All things considered, Python is clearly dominant; languages like Rust and TypeScript are gathering steam. While learning Python and Rust could create new prospects, for web developers staying current with JavaScript and TypeScript is still absolutely vital. The terrain is continually changing, hence staying ahead depends on closely observing these trends!
Stackoverflow, though, provides a bit different statistic in their yearly research of the most used coding languages, with JavaScript in the first place:
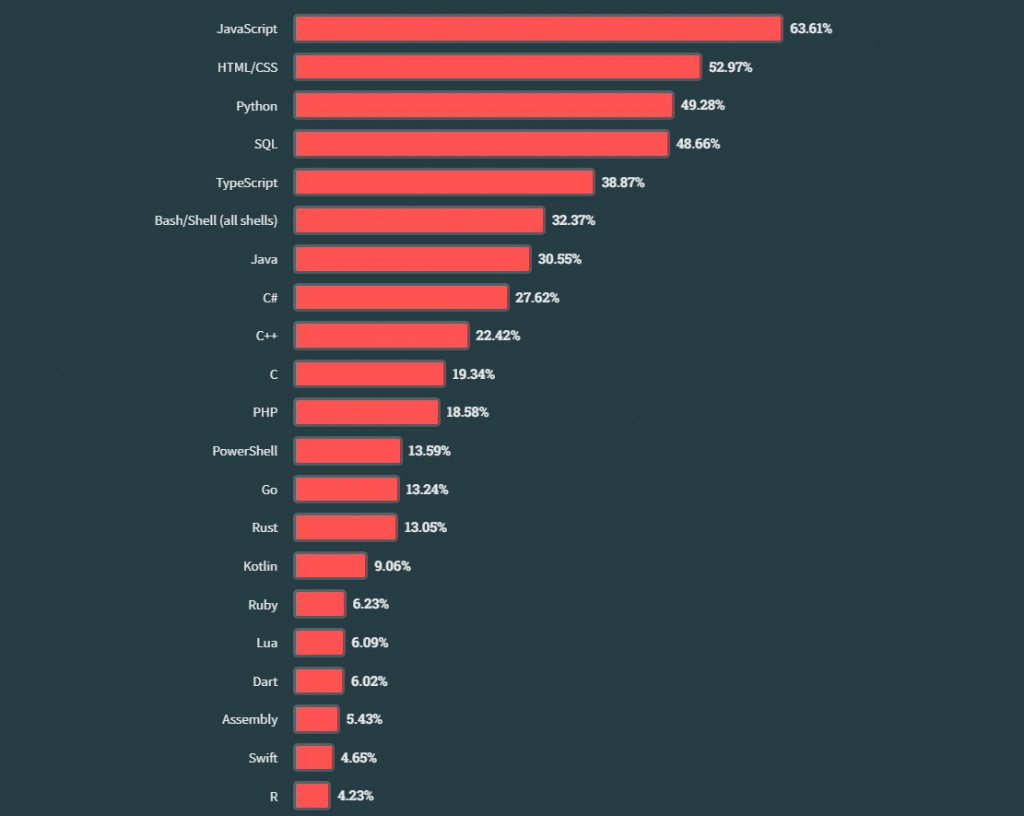
Overall, Python’s versatility and ease of learning make it a highly demanding language in the tech industry, with a wide range of applications across various domains.
The Future is Now: Best Coding Language to Learn in 2024
The choice depends on your interests and career goals, however, there are some universal options you can go for.
For example, Python. As we said, it’s extremely popular now and is often recommended for beginners due to its simplicity and readability. It has a straightforward syntax that makes the code easy to learn and understand. So it’s an excellent choice for those new to programming.
JavaScript is another language that can be a good starting point if you want to build interactive websites and web applications. There are many resources and tutorials to help you learn JavaScript.
What about kids? They need a different, more engaging approach. Scratch is a visual programming language developed by MIT that is specifically designed for children. It uses a block-based coding interface that allows users to drag and drop code blocks to create animations, games, and interactive stories. So kids can learn fundamental programming concepts without the complexity of text-based coding.
Specialized Sectors and Their Preferred Languages
iOS Development
For this sector, consider learning Swift. It is used to build iOS and macOS X applications for various Apple devices, like iPhone, iPad, and Apple Watch. Since they are quite popular, studying or including Swift as a part of the main toolkit is a wise decision.
This iOS programming language is a powerful and versatile tool created by Apple. It offers a modern syntax, strong type safety, and performance optimization, making it a popular choice among developers.
Mobile Banking App by Shakuro
Game Development
There are several languages commonly used, depending on the game engine and platform. Some popular options include C++, C#, and JavaScript.
C++ is often used for high-performance game development, while JavaScript is used for developing web-based games and with game engines such as Phaser and Three.js.
Still, one of the best programming languages for game development is C#. It is commonly used with the Unity game engine. This means there is a large community of developers, tutorials, and resources for troubleshooting or learning. C# is also supported on multiple platforms, so your games can be easily ported to other devices and operating systems.
Data Science
In this field, Python is at the top of the mountain due to its versatility, extensive library ecosystem, and easy-to-learn syntax. Python libraries such as Pandas, NumPy, and scikit-learn are widely used for data manipulation, analysis, and machine learning tasks.
R is another data science programming language used for statistical analysis, machine learning, data visualization, and manipulation. It provides a free and open-source platform, featuring a rich ecosystem of packages, libraries, and tools to expand the functionality.
Embedded Systems
For embedded systems, it is ideal to choose languages like C and C++ due to their efficiency, low-level capabilities, and control over hardware. They are well-suited for developing firmware, device drivers, and real-time systems, where direct interaction with hardware components and peripherals is required.
C is a popular embedded systems programming language due to its speed, portability, and close-to-the-hardware nature. It allows developers to write code that directly manipulates memory addresses and hardware registers. C++ builds upon C by providing additional features like object-oriented programming, which allows for better code organization, reuse, and modularity.
Artificial Intelligence
The best programming languages for AI include Python, R, and Java. Python is the preferred language for developing AI applications because of its simplicity, extensive libraries for machine learning and deep learning, as well as accessibility.
R is often used for statistical analysis and data visualization in Artificial Intelligence research. As for Java, you can use it for building applications that require high performance, scalability, and integration with other enterprise systems.
AI Insurance Web Design Concept by Shakuro
Understanding Programming Paradigms
Let’s start with recapping the definition. A programming paradigm is a fundamental style or approach that defines the structure, design, and implementation of software systems. It outlines the rules, principles, and concepts that guide how code is written, organized, and executed in a programming language.
Several programming paradigms represent different philosophies and methodologies. We’ll dwell on some of them:
Procedural Programming
It focuses on breaking down a program into smaller, reusable procedures or functions that have a specific purpose or task. The code is organized and executed in a linear sequence of instructions, where the program’s control flow is determined by the order in which statements are written.
Languages that follow this paradigm include C, Pascal, and BASIC. They provide constructs for defining procedures, handling data, and controlling the flow of execution within the program.
While procedural programming is straightforward to understand, it can become complex and difficult to maintain as the program grows in size and scope. This paradigm lacks encapsulation and information-hiding features, which can lead to code duplication, decreased modularity, and spaghetti code in large projects.
Functional Programming
This one treats computation as the evaluation of mathematical functions and avoids changing state or mutable data. Functions are first-class citizens, meaning they can be passed around as arguments, returned as values, and stored in data structures. This paradigm is based on the principles of declarative programming, immutability, and higher-order functions.
Haskell, Scala, Clojure, and Erlang follow the functional programming paradigm. They provide features such as higher-order functions, immutable data structures, pattern matching, and type inference that support functional programming principles.
However, this paradigm may have a steeper learning curve for programmers transitioning from imperative or object-oriented paradigms.
Object-Oriented Programming
OOP organizes and models software systems as objects, which are instances of classes. It emphasizes the concept of “objects” rather than “actions” and data rather than logic, allowing developers to create reusable and modular code structures. In OOP, objects have attributes (properties) and behaviors (methods) that define their state and functionality.
Object-oriented programming is widely used in software development due to its ability to promote code reusability, modularity, and maintainability. It allows developers to create scalable and flexible software systems by organizing code into smaller, manageable units (objects) that interact with each other.
Object-oriented programming languages such as Java, C++, C#, Python, and Ruby provide built-in support for implementing OOP concepts and creating robust and efficient applications.
Script-Based Programming
Also known as scripting, it is a type of paradigm that involves writing scripts or sequences of commands that are executed by a runtime environment or scripting engine. Scripting languages are often used for automating tasks, performing repetitive operations, and controlling software applications. Unlike traditional programming languages that are compiled into machine code, scripts are executed line by line by an interpreter.
Popular scripting languages include JavaScript, Python, Perl, Ruby, Bash, PowerShell, and PHP. Each language has its strengths and is commonly used in different domains such as web development, system administration, automation, data processing, and more.
Contact Manager App Design Concept by Conceptzilla
Summing up the tier list
Now you know the top programming languages in 2024 for different spheres in the U.S. The options are diverse, and you can choose based on your specific needs and preferences.
The popularity varies depending on factors such as industry trends, job market demand, and project requirements. As technology advances and new languages emerge, you need to stay informed and adaptable to keep up with the ever-changing landscape.
Do you need a custom app development based on cutting-edge technologies? Reach out to us and we’ll build a functional product.
The article was originally published in October 2022 and was updated in April 2024 to make it more relevant and comprehensive.